메시징 큐의 학습이 필요하여 카프카(KAFKA)를 학습하고 정리하는 글입니다.
출처
데브원영님의 카프카 강의
1. 카프카(KAFKA)란?
- Apache Kafka는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 오픈 소스 분산 이벤트 스트리밍 플랫폼이다.
- 비동기 처리를 위한 메시징 큐의 한 종류이지만, 동기 처리도 가능하다!
- 기본적으로 프로듀서/컨슈머 구조를 가진다.
1-1. 카프카는 메일 시스템과 비슷하다!

- 메일 시스템
- 보내는 사람은 메일 서버로 메시지를 보낸다. (메일 서버에 저장됨)
- 받는 사람은 원할 때 메일을 볼 수 있다.
- 카프카
- 프로듀서는 카프카로 메시지를 보낸다.
- 컨슈머는 카프카에 저장되어 있는 메시지를 필요할 때 가져옴
2. 카프카 Quickstart를 통해 설치/학습해보자
- 카프카의 간단한 테스트 환경을 위해선 최소 3대가 필요하다.
- 주키퍼와 카프카를 동일한 서버로 구성해도 좋다.
- 주키퍼: 대규모 분산 시스템에서 데이터를 저장하고 관리하는 도구
더보기🗣 주키퍼는 카프카 클러스터의 메타데이터와 상태를 저장하고 관리하는데 사용됩니다. 예를 들어, 주키퍼는 카프카 브로커(Broker)가 라이브 상태인지, 토픽(Topic)과 파티션(Partition)이 어디에 저장되는지, 카프카 컨슈머(Consumer) 그룹이 어떤 오프셋(Offset)을 읽고 있는지 등을 추적합니다.
2-1. 설치과정 (by. docker)
설치과정은 다음 순서를 따르면 된다.
- 카프카 설치
- docker pull wurstmeister/kafka
- ZooKeeper 설치
- docker pull wurstmeister/zookeeper
- yml 설정 (docker-compose.yml)
- KAFKA_ADVERTISED_HOST_NAME: localhost
- KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR
- 토픽의 복제 수를 의미한다.
- 실제 운영 환경에서는 안정으로 보존/복구 할 수 있도록 2 또는 3으로 factor를 늘린다고 한다.
version: '2' services: zookeeper: image: wurstmeister/zookeeper container_name: zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka container_name: kafka ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 volumes: - /var/run/docker.sock:/var/run/docker.sock
2-2. 실행하기
1. 실행
docker-compose up -d2. 접속
docker container exec -it kafka bash3. 카프카 용어
기본 용어는 토픽, broker, Replication, 파티셔너, lag가 있다. 하나씩 살펴보면 다음과 같다.
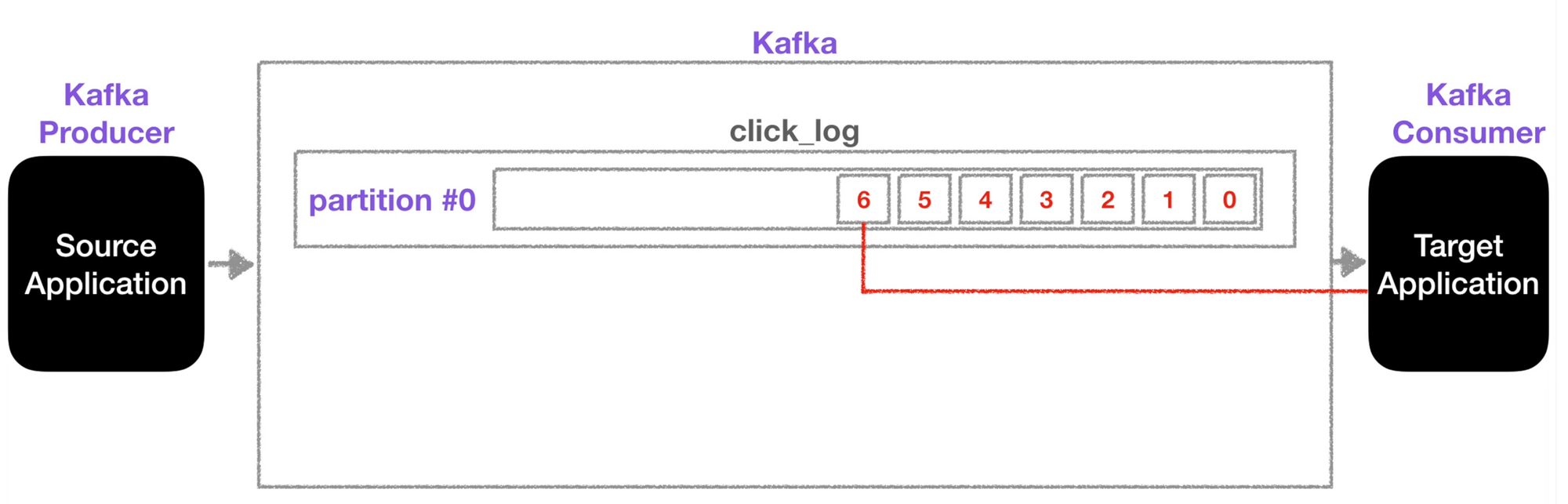
3-1. 토픽(=큐)
- 토픽은 이름을 가질 수 있다.
- 하나의 토픽(논리적)은 여러개의 파티션(물리적)을 가진다.
- 들어온 순서대로 실행된다.
- 0, 1, 2, 3, 4, 5, 6 순서로 실행된다.
- consumer가 수행하더라도 파티션의 record들이 삭제되지 않는다.
- 0, 1, 2, 3, 4, 5 가 수행되었더라도 바로 삭제되지 않는다.
- 삭제 정책을 구성하고 보존기간을 초과하면 삭제한다.
3-2. broker
카프카가 설치되어 있는 서버 단위
- 위에 언급했다 싶이, 보통 3개 이상의 broker 구성하여 사용하는 것을 권장한다.
- 카프카 클러스터는 여러 개의 브로커로 이루어진 분산 시스템을 의미한다.
3-3. Replication
partition의 복제본이다. broker가 3이면 replication은 4이상 될 수 없다.
- Leader partition: 원본 partition
- Follower partition: 복제본 partition
- ISR(In Sync Replica): Leader partition + Follower partition
- 1: Leader partition만 존재
- 2: Leader partition 1개, Follower partition 1개
- 3: Leader partition 1개, Follower partition 2개
🗣 만약 브로커 3대, 파티션 1개의 replication이 1인 topic 라면?
- 브로커 3대중 1대에 해당 토픽의 정보가 저장된다. 어떻게 사용할까? (by Producer)
- 0, 1, all 3개의 옵션을 선택해 ack할 수 있다.
- 0: Leader partition에 전송, 응답값이 없다. 즉, 정상적으로 전송되었는지, 실패했는지 알 수 없다.
- 1: Leader partition에 전송, 응답값이 존재한다.
- Follower partition에 복제 되었는지 알 수 없다.
- all: Leader partition에 전송, 응답값이 존재한다.
- Follower partition에 복제 되었는지 알 수 있다.
- 전부 다 전송하기에 속도가 느림
3-4. 파티셔너(Partitioner)
Producer가 데이터를 보내면 파티셔너를 통해서 브로커로 전송한다.
- 어떤 파티션에 레코드가 들어갈 지 결정한다.
- 메시지 key가 존재하는 경우 항상 같은 파티션에 들어가기 때문에 순서가 보장된다.
- 파티셔너 인터페이스가 제공되어 어떤 파티션에 데이터를 넣을지 결정할 수 있다.
- 파티션 용량이 꽉 차는 상황에서 새로운 레코드를 삽입하려고 하면, 저장공간이 없기에 레코드는 버려진다.
3-5. 카프카 lag
offset: 파티션 내에서 메시지의 위치 정보
- kafka consumer lag: 아래 두 개의 수 차이(숫자 차이를 통해 알 수 있음)를 의미한다.
- consumer가 마지막으로 읽은 offset
- producer가 마지막으로 넣은 offset
- 파티션마다 lag가 존재한다.
- 오픈소스 lag 모니터링 어플리케이션이 존재한다(Burrow).
- 다음의 상태를 보여준다.
- ERROR
- WARNING
- OK
4. 토픽을 통해 실습해보기
4-1. 토픽 CRD(Create, Read, Delete)를 해보자
토픽을 생성하려면 kafka-topics.sh 스크립트를 사용한다.
- 생성: —create —topic
kafka-topics.sh --create --topic <토픽명> --partitions 1 --replication-factor 1 --bootstrap-server <bootstrap-server>
kafka-topics.sh --create --topic jero-topic --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
// 파티션 0~99가 생성된다
kafka-topics.sh --create --topic junit-test-topic --partitions 100 --replication-factor 1 --bootstrap-server localhost:9092
- 전체 토픽 조회
kafka-topics.sh --list --bootstrap-server localhost:9092
- 단일 토픽 조회
// 단일
kafka-topics.sh --describe --topic <topic-name> --bootstrap-server <bootstrap-server>
kafka-topics.sh --describe --topic junit-test-topic --bootstrap-server localhost:9092
// 단일 + 파티션번호
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic junit-test-topic --partition 1 --from-beginning
- 삭제
kafka-topics.sh --zookeeper <zookeeper_host>:<zookeeper_port> --delete --topic junit_test_topic
kafka-topics.sh --zookeeper zookeeper:2181 --delete --topic junit-test-topic
4-2. 프로듀서 실행 (토픽에 메시지 전송)
토픽에 메시지를 전송하려면 kafka-console-producer.sh 스크립트를 사용한다.
- 메시지는 key, value 형태로 전송된다.
- key, value 형태가 아니라면 일반적으로 key값은 null이 된다
kafka-console-producer.sh --topic <토픽명> --bootstrap-server localhost:9092
kafka-console-producer.sh --topic jero_topic --bootstrap-server localhost:9092
> key1:value1
> key2:value2
> ctrl + c
4-3. 컨슈머 실행 (토픽 메시지 읽기)
토픽의 메시지를 읽기 위해 kafka-console-consumer.sh 스크립트를 사용한다.
- —from-beginning: 처음부터 메시지 읽기
kafka-console-consumer.sh --topic <토픽명> --from-beginning --bootstrap-server localhost:9092
kafka-console-consumer.sh --topic jero_topic --from-beginning --bootstrap-server localhost:9092
4-4. 토픽 내의 파티션 확인하기
kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic junit_test_topic
5. 스프링에서 카프카 연동
5-1. 의존성 추가
dependencies {
implementation 'org.springframework.kafka:spring-kafka'
implementation 'com.fasterxml.jackson.core:jackson-databind'
}
5-2. 프로듀서/컨슈머 생성
- 프로듀서
@Service
public class CustomKfkaProducer {
private static final String TOPIC = "first_jero_topic";
private final KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public CustomKfkaProducer(KafkaTemplate kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
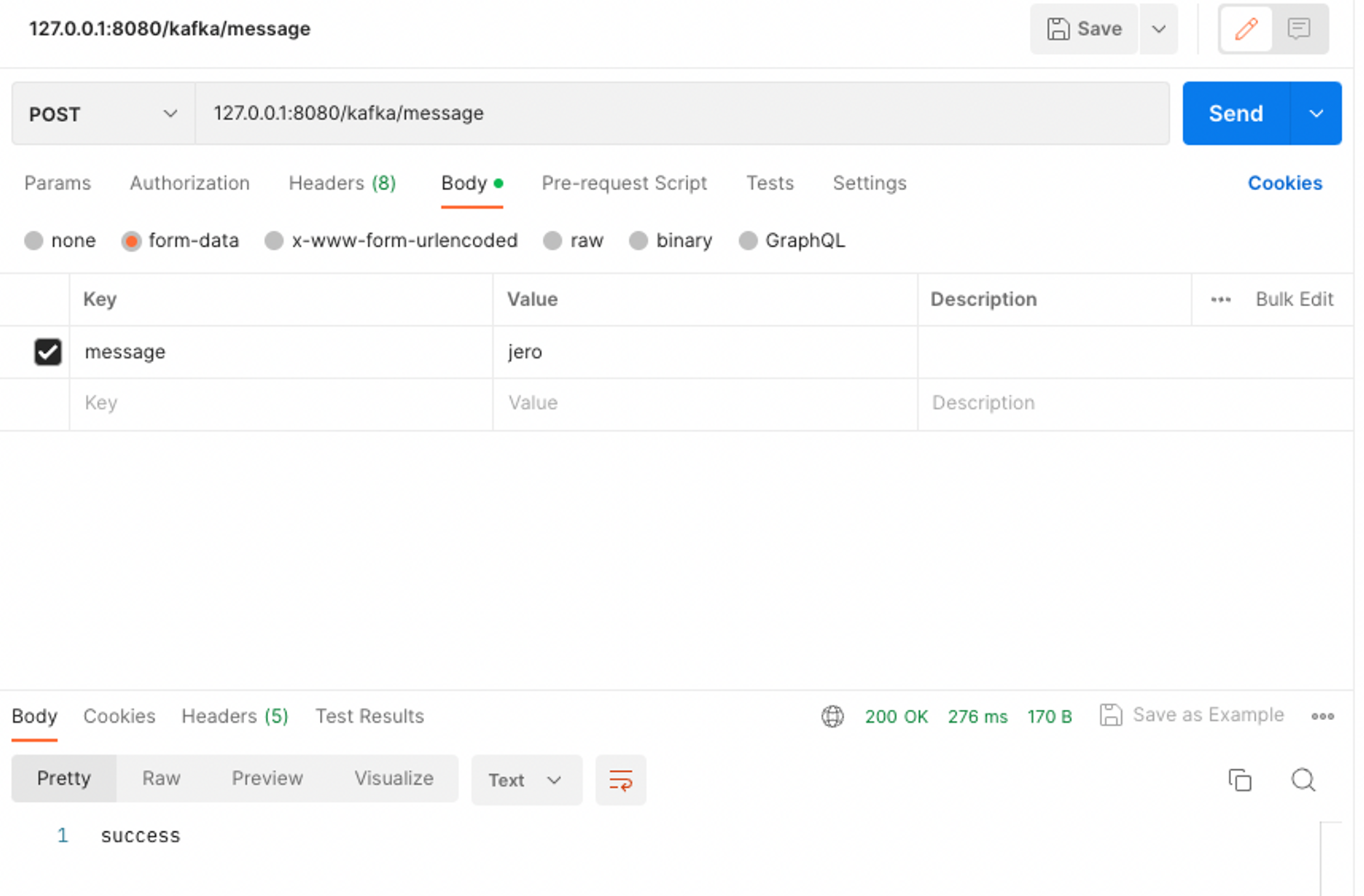
public void sendMessage(String message) {
System.out.println(String.format("Produce message : %s", message));
this.kafkaTemplate.send(TOPIC, message);
}
}- 컨슈머
@Service
public class CustomKafkaConsumer {
@KafkaListener(topics = "first_jero_topic", groupId = "group1")
public void consume(String message) {
System.out.println(String.format("Consumed message : %s", message));
}
}5-3. 결과
5-4. 토픽 생성 시점(By Spring Kafka)
- 어플리케이션 실행 시점
- @KafkaListener를 사용하면 어플리케이션이 실행될 때 토픽이 생성된다.
- API 호출 시점
- 프로듀서를 통해 메시지를 토픽에 전달할 때, 토픽이 없다면 생성 후 전달한다.
public void sendMessage(String message) {
this.kafkaTemplate.send("topic_name", message);
}'공부 > Spring' 카테고리의 다른 글
| 객체지향과 의존성 (0) | 2022.11.01 |
|---|---|
| HikariCP란 무엇이고 어떤 풀 사이즈를 적용해야 할까? (0) | 2022.10.20 |
| QueryDSL에서 수정, 삭제 벌크연산 하는방법을 알아보자 (0) | 2022.08.26 |
| [QueryDSL] 동적쿼리를 해결해보자 (0) | 2022.08.26 |
| [QueryDSL] 프로젝션(SELECT 대상)에 따라 다른 결과를 가져와 보자 (0) | 2022.08.26 |




댓글